FARSEC = Filtering And Ranking SECurity Bug Reports
Table of Contents
Overview of FARSEC | Results | Resources
When mislabelled security bug reports (SBRs) are publicly disclosed in bug tracking systems, this presents malicious actors with a window of opportunity to exploit these security vulnerabilities.
Bug tracking systems may contain thousands of bug reports, where relatively few of them are security related. Therefore, security engineers are faced with the problem of trying to find a needle in a haystack. In other words, security engineers may need to comb through hundreds or thousands of bug reports in order to find actual SBRs.
To help ease the burden of the search, they employ prediction models, usually based on text mining methods.
Our FARSEC framework offers a novel approach to reduce the mislabelling of security bug reports by text-based prediction models. Our approach is based
on the observation that, it is the presence of security related keywords in both security and non-security bug reports (NSBRs), which leads to mislabelling.
Based on this observation FARSEC includes a method for automatic identification of these keywords and for scoring bug reports according to how likely they are to be labelled as SBRs. We found that our approach offers an effective and usable solution for reducing the mislabeling of SBRs in text-based prediction models.
Overview of FARSEC
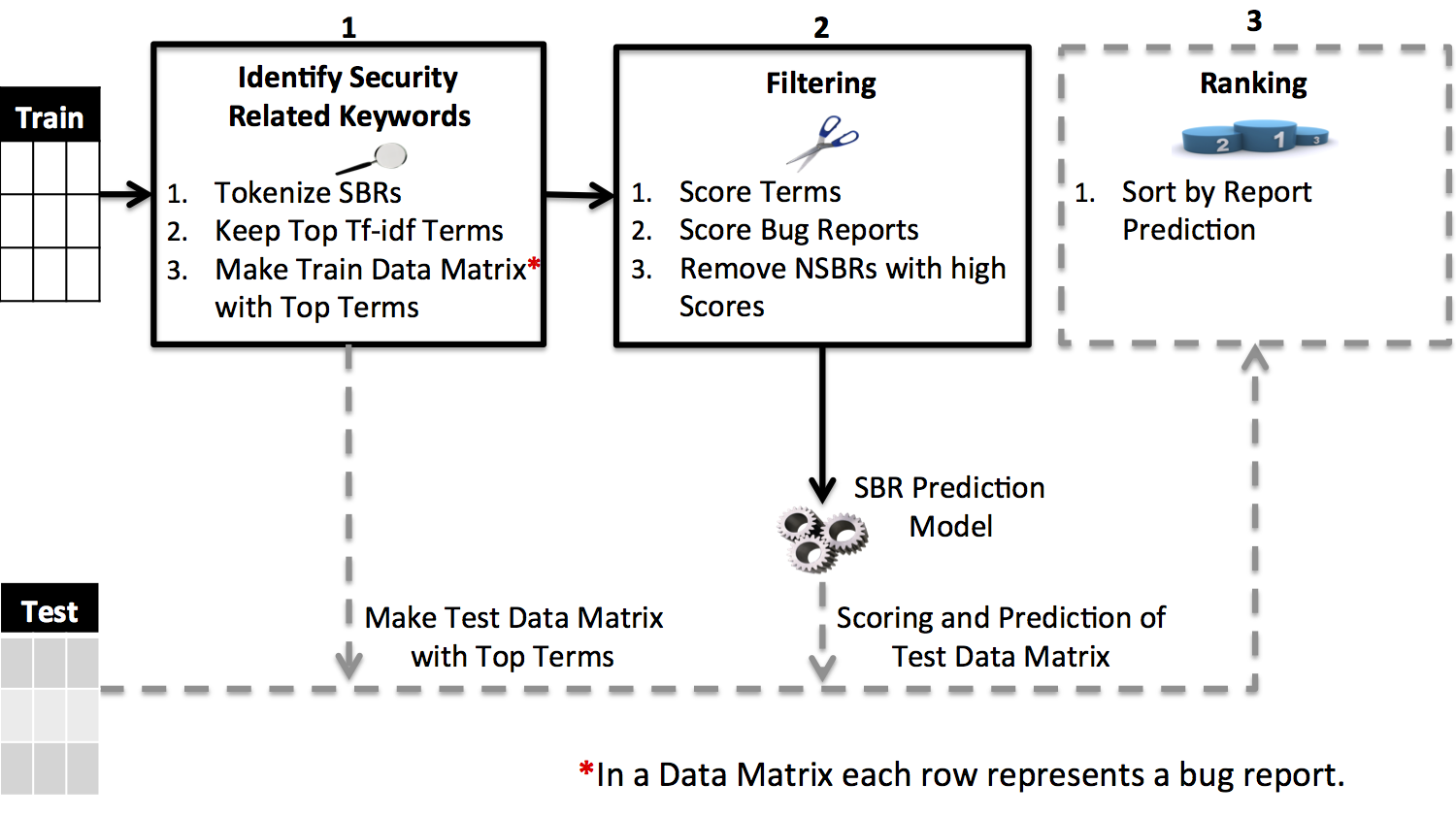
When building prediction models, FARSEC automatically identifies and removes non security bug reports containing security related keywords. The overview of FARSEC above, shows its three main stages:
- identifying security related keywords;
- filtering via the scoring of security related keywords and bug reports; and
- ranking based successive sorting and prediction.
1. Identifying Security Related Keywords
To identify security related keywords from bug reports, we tokenize the SBRs and then calculate the tf-idf values of each term. We consider the hundred terms with the highest tf-idf values to be security related keywords. These keywords are then used to build term-document matrices.
2. Filtering Bug Reports
FARSEC filtering is about removing NSBRs with security related keywords from the term-document matrix. We score the keywords and use these scores to calculate an overall score for bug reports, which contain all, some, or none of the security related keywords. This is similar to text filtering approaches used to classify emails into spam and non-spam.
3. Ranking Bug Reports
When dealing with imbalanced data, the results of prediction models can yield a large number of false positives i.e. NSBRs predicted as SBRs. Therefore, after identifying predicted SBRs, we generate a useful list of ranked bug reports so that the majority of actual SBRs are closer to the top of the list.
Results
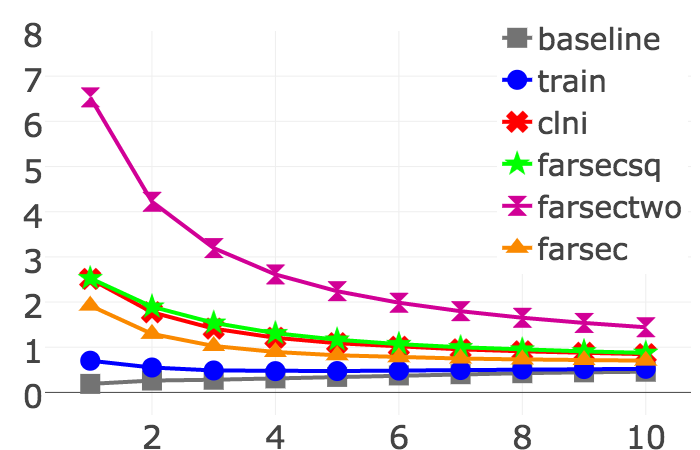
The chart shows the performance of three versions of FARSEC with CLNI (Closest List Noise Identification), baseline (the order the bug reports enter the tracking system), and train (based on predictions from models built with unfiltered bug reports).
In our experiments, we demonstrated that FARSEC improves the performance of text-based prediction models for security bug reports in 90 percent of the cases. Specifically, we evaluated it with a total of 45,940 bug reports from Chromium and four Apache projects. We found that with FARSEC, we reduced the number mislabelled security bug reports by 38 percent.
Resources
| Resources | |
|---|---|
| Code | FARSEC implemented in clojure |
| Paper | Text Filtering and Ranking for Security Bug Report Prediction |